Perhaps We Have Just Crossed Another Inflection Point
There is a moment in the history of technology when something stops being impressive and simply becomes normal.
It almost never happens with a triumphant announcement, a press conference, or an exponential chart shown on a stage. It happens in a more ordinary way. You are sitting on a plane, crossing an ocean, without an internet connection. You open your computer and try to work with what you have. Not the most powerful model in the world. Not the most expensive cloud service. Not the oracle hidden behind a premium subscription. Just a local, mid-sized model running without asking anyone for permission.
Last week, during an intercontinental trip, I found myself in exactly that situation. With no internet connection, I started using two mid-small open-weight models: Gemma 4 31B and Qwen 3.5 35B. I was not expecting miracles. I expected decent answers, maybe useful for taking notes, organizing a few ideas, or having a not-too-demanding technical conversation.
Instead, I was surprised.
I am not talking about advanced coding, complex agentic tasks, tool usage, web browsing, automation, or long multi-step reasoning. In those areas, larger closed models still have an obvious advantage. I am talking about something much more common: conversations, explanations, summaries, brainstorming, reflections, general questions, and conceptual reasoning.
In other words, what most people actually do with AI.
And there, the surprise was real. I started comparing some of the responses with conversations I had previously had with GPT-5.4. In several cases, the local models were not merely “good enough.” They were excellent. Sometimes more direct. Sometimes less ingratiating. Sometimes even better.
This does not mean that a 30 or 35 billion parameter model is “better” than a closed frontier model. That would be a naive conclusion. But it does mean something perhaps more important: for a large number of everyday use cases, the difference is becoming irrelevant.
And that is where the inflection point begins.
For years, we have thought about AI as if there were only one natural direction: larger and larger models, more and more expensive, increasingly centralized, increasingly dependent on the cloud. Artificial intelligence seemed destined to become a new imperial infrastructure: a few large labs, a few massive data centers, a few expensive subscriptions, and billions of users connected to remote intelligences.
But perhaps that was only the first phase.
In the first phase, intelligence had to live in the temple. In the second, it begins to live in the home.
Most users treat AI as a smarter version of Google. They ask questions. They request summaries. They look for advice. They want to understand a concept, write an email, prepare for a meeting, translate a text, generate ideas, or explore a doubt. For these use cases, how many people would truly notice the difference between a closed cloud model and an open-weight model running on their own PC?
Very few.
And once the quality difference becomes small, all the other differences become enormous.
Privacy. Cost. Control. Latency. Data sovereignty. The ability to work offline. The ability to customize. The ability not to send every fragment of your life, your work, or your company to a remote service.
For a consumer, this is convenient. For an enterprise, it is strategic. For a government, it is geopolitical.
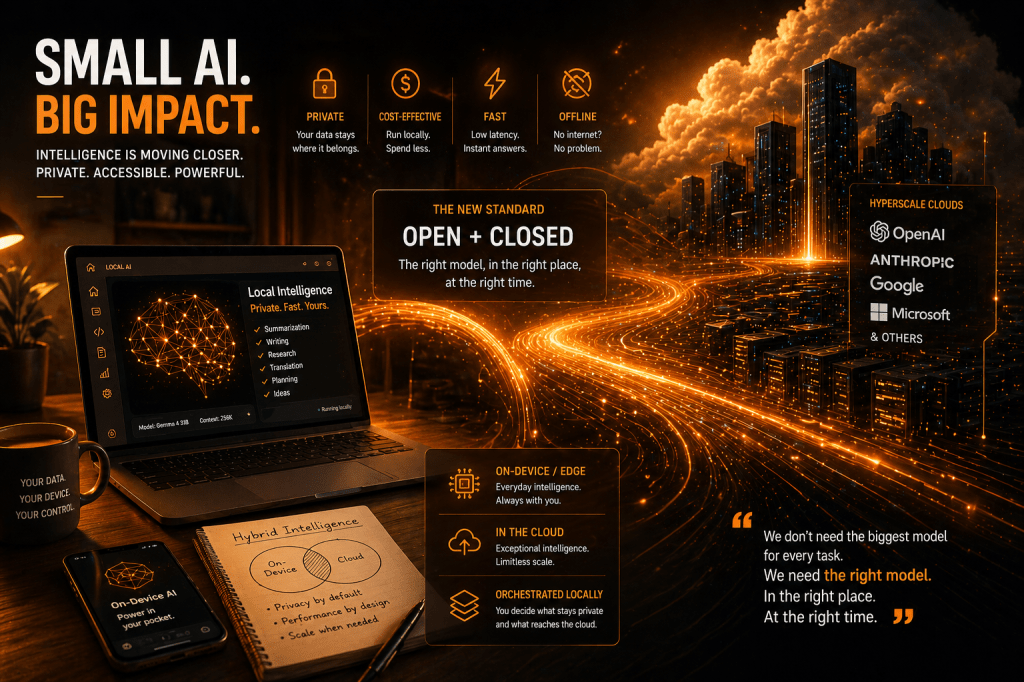
The point is not that open-weight models will defeat closed models. That is the wrong frame. The real transition is from open vs. closed to open + closed.
Closed models will continue to dominate extreme use cases: complex reasoning, advanced multimodality, deep coding, autonomous agents, tool orchestration, scientific tasks, and emergent capabilities. But open and local models are becoming good enough for the ordinary work of intelligence: reading, explaining, discussing, summarizing, classifying, transforming, advising.
And in economic history, the ordinary is almost always more important than the extraordinary.
Google itself presents Gemma 4 as a family of open-weight models designed for generation, question answering, summarization, and reasoning, with the possibility of tuning and deployment in custom projects. The official model card describes multimodal models, pre-trained and instruction-tuned variants, a context window of up to 256K tokens, and broad multilingual support. Google also claims that Gemma 4 31B ranks among the top open models on the Arena AI text leaderboard and outperforms much larger models in some specific comparisons.
This matters because it changes the narrative. Until yesterday, the small model was often perceived as a poor version of the large model. A temporary compromise. A developer toy. Something to put in the attic while waiting for better times.
Perhaps those better times have arrived.
Of course, we should avoid easy enthusiasm. Benchmarks are useful, but they are not reality. A leaderboard does not tell you how a model behaves inside your company, with your data, your users, your errors, and your legal responsibilities. Above all, we should not confuse “open weight” with “open source” in the full sense. Having the weights does not necessarily mean having everything: datasets, training recipes, pipelines, filters, design decisions.
Still, the signal is clear: intelligence per parameter is improving rapidly.
Qwen 3.5 points in the same direction. The Hugging Face page for Qwen3.5-35B-A3B shows an ecosystem oriented toward local deployment and efficient serving; industry sources describe the Qwen 3.5 family as broad, ranging from edge models to much larger ones, with attention to tool calling, agentic benchmarks, and lighter deployment.
This explains why the debate about model size is becoming less interesting. The question is no longer only: “How large is the model?” The question becomes: “How much useful intelligence can it produce per watt, per dollar, per gigabyte, per second, and per acceptable level of risk?”
It is a much less spectacular question. But it is the question that decides markets.
The closed-source giants will not disappear. In fact, their development plans are not necessarily exaggerated. Today, only a minority of the world’s population uses AI systematically. If adoption grows by even a few percentage points, demand for compute capacity will explode. There will be room for enormous models, hyperscale clouds, advanced agents, and specialized systems.
But there will also be a second world.
An on-edge world.
A world where a growing share of artificial intelligence runs on laptops, phones, company servers, factories, hospitals, vehicles, and personal devices. A world where the cloud does not disappear, but becomes the place for exceptional tasks, while the local device handles the normal ones.
This is where hardware vendors may find a new narrative. For years, smartphones and laptops became more powerful without giving the average user a truly convincing reason to care. Better screens, better batteries, better cameras — but the question remained: what is all this power for?
Now the answer may be: it is for running private intelligence.
It is no coincidence that Apple is increasingly emphasizing on-device AI. In the official announcement of the M5 chip, Apple speaks of improvements for Apple Intelligence, the Neural Engine, unified memory, and higher performance for local AI models and features. Other observers have also noted how the M5 pushes AI acceleration, memory, and local generation, while still requiring caution when discussing real-world performance outside benchmarks.
Apple often appears to be behind in generative AI. But that may be too superficial a reading. If the next chapter is not only “who has the most powerful chatbot in the cloud,” but “who can bring useful, private, integrated intelligence onto the device,” then Apple may be in a stronger position than it seems.
We will see whether and how much of this emerges at WWDC 2026. But the industrial direction is clear: AI will not live only in data centers. It will also live in devices.
This opens a fork in the road for companies as well.
Until now, many enterprises have lived with an unresolved tension around AI. On one hand, they want to use powerful models. On the other, they have confidential data, regulatory constraints, intellectual property, trade secrets, customer contracts, and compliance responsibilities. The cloud is convenient, but not always reassuring. The local model is reassuring, but until recently it was not good enough.
If that second condition changes, everything changes.
A company will be able to imagine much more sensible hybrid architectures: local models to handle sensitive context, internal documents, confidential conversations, classifications, retrieval, summaries, and everyday workflows; cloud models for the most difficult tasks, provided they are stripped of sensitive context. Orchestration can happen locally. The private part remains private. The “intelligent but non-secret” part can go to the cloud.
This, in my view, is one of the most interesting directions: not fine-tuning everywhere, not miraculous small models for everything, but intelligent local orchestration.
I remain skeptical about fine-tuning. It is useful in some niches: specific languages, repetitive formats, highly controlled domains, vertical classifications, company tone of voice. But for many use cases, it is overestimated. Often companies do not need to train a model. They need to give it the right context, at the right time, with the right level of authorization, and make sure data does not go where it should not go.
The real innovation may be less romantic than expected: routing, caching, retrieval, policy, privacy, distillation, quantization, continuous evaluation. Not a single omnipotent brain, but an efficient bureaucracy of small specialized brains.
Andrej Karpathy has also repeatedly promoted a similar idea: not every path goes through endlessly increasing scale; data quality, knowledge compression, and training efficiency matter enormously. In his interview with Dwarkesh Patel, Karpathy stresses that many of AI’s current problems will not be solved simply by adding scale, and that the path toward reliable agents will still require years of work. The more extreme version of this thesis — the idea that a very small model, trained on exceptional data, could approach capabilities currently obtained with enormous models — should be taken with caution. Not because it is absurd, but because if it were simple, OpenAI, Anthropic, Google, and the others would already have done it.
They are not fools.
But it is plausible that there is still a great deal of waste. Waste in the data. Waste in the tokens. Waste in the parameters. Waste in inference. Waste in the everyday use of enormous models for trivial tasks.
And waste is exactly what creates economic opportunity.
When a technology is born, it is used inefficiently. The first computers occupied entire rooms to perform calculations that today a watch can do. The first mobile phones looked like suitcases. The first truly useful language models seemed destined to live only in enormous data centers. Then the technology matures, miniaturizes, distributes itself, and becomes invisible.
Perhaps we are at the beginning of that phase.
Not tomorrow morning. Not with a sudden revolution. Not with the collapse of the cloud giants. But with a slow redistribution of intelligence.
The cloud will keep the frontier. The edge will conquer everyday life.
Closed models will sell the maximum. Open-weight models will provide — or rather enable — the sufficient. And in most markets, the sufficient wins more often than the maximum.
That is why the experience on that plane felt more important than it was reasonable to admit. Not because Gemma 4 or Qwen 3.5 are “the end” of closed models. They are not. But because they made me physically perceive a threshold: the moment when a local model stops feeling like a demo and starts feeling like a colleague.
Not a perfect colleague. Sometimes slow. Sometimes verbose. Sometimes imprecise. But available, private, inexpensive, offline, and improvable.
In 2026, perhaps the question will no longer be: “What is the best model in the world?”
It will be: “What is the smallest model that does the job well enough?”
And that is a dangerous question for many business models.
Because when customers discover that they do not always need the temple, they begin building a chapel at home.

Leave a comment