Forse abbiamo appena attraversato un altro punto di inflessione
C’è un momento, nella storia della tecnologia, in cui una cosa smette di essere impressionante e comincia semplicemente a essere normale.
Non succede quasi mai con un annuncio trionfale, una conferenza stampa o un grafico esponenziale mostrato su un palco. Succede in modo più banale. Sei seduto su un aereo, attraversi un oceano, non hai connessione internet, apri il computer e provi a lavorare con quello che hai. Non il modello più potente del mondo. Non il servizio cloud più costoso. Non l’oracolo chiuso dietro un abbonamento premium. Solo un modello locale, medio-piccolo, che gira senza chiedere il permesso a nessuno.
La settimana scorsa, durante un viaggio intercontinentale, mi sono trovato esattamente in quella situazione. Senza connessione internet, ho iniziato a usare due modelli open weight di dimensione medio-piccola, Gemma 4 31B e Qwen 3.5 35B. Non mi aspettavo miracoli. Mi aspettavo risposte dignitose, magari utili per prendere appunti, riordinare qualche idea, fare conversazione tecnica non troppo impegnativa.
Invece mi sono sorpreso.
Non sto parlando di coding avanzato, task agentici complessi, uso di strumenti, navigazione web, automazioni o ragionamenti lunghi a più passaggi. Su quei terreni i modelli più grandi e chiusi hanno ancora un vantaggio evidente. Sto parlando di qualcosa di molto più comune: conversazioni, spiegazioni, sintesi, brainstorming, riflessioni, domande generali, ragionamenti concettuali.
Cioè, in pratica, quello che la maggior parte delle persone fa davvero con l’AI.
E lì la sorpresa è stata netta. Ho iniziato a confrontare alcune risposte con conversazioni che avevo fatto con GPT-5.4. In diversi casi, le risposte dei modelli locali non erano semplicemente “abbastanza buone”. Erano ottime. A volte più dirette. A volte meno compiacenti. A volte persino migliori.
Questo non significa che un modello da 30 o 35 miliardi di parametri sia “migliore” di un frontier model chiuso. Sarebbe una conclusione ingenua. Ma significa qualcosa di forse più importante: per una grande quantità di usi quotidiani, la differenza sta diventando irrilevante.
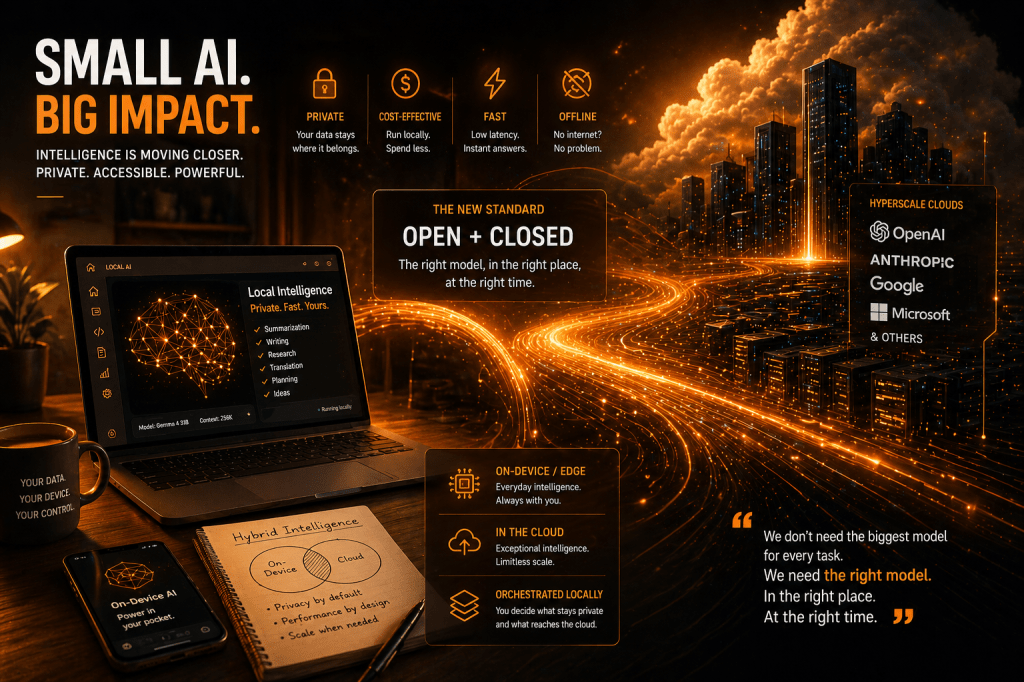
Ed è qui che inizia il punto di inflessione.
Per anni abbiamo ragionato sull’AI come se esistesse una sola direzione naturale: modelli sempre più grandi, sempre più costosi, sempre più centralizzati, sempre più dipendenti dal cloud. L’intelligenza artificiale sembrava destinata a diventare una nuova infrastruttura imperiale: pochi grandi laboratori, pochi grandi data center, pochi grandi abbonamenti, miliardi di utenti collegati a intelligenze remote.
Ma forse questa era solo la prima fase.
Nella prima fase, l’intelligenza doveva abitare nel tempio. Nella seconda, comincia ad abitare nella casa.
La maggior parte degli utenti usa l’AI come una versione più intelligente di Google. Fa domande. Chiede riassunti. Cerca consigli. Vuole capire un concetto, scrivere una mail, preparare una riunione, tradurre un testo, generare idee, discutere un dubbio. Per questi casi d’uso, quanti si accorgerebbero davvero della differenza tra un modello chiuso in cloud e un modello open weight che gira sul proprio PC?
Pochi.
E se la differenza qualitativa diventa piccola, allora le altre differenze diventano enormi.
Privacy. Costo. Controllo. Latenza. Sovranità del dato. Possibilità di funzionare offline. Possibilità di personalizzazione. Possibilità di non mandare ogni frammento della propria vita, del proprio lavoro o della propria azienda verso un servizio remoto.
Per un consumatore, questo è comodo. Per un’azienda enterprise, è strategico. Per un governo, è geopolitico.
Il punto non è che i modelli open weight vinceranno contro i modelli chiusi. Questa è una cornice sbagliata. La vera transizione è da open vs closed a open + closed.
I modelli chiusi continueranno a dominare i casi estremi: ragionamento complesso, multimodalità avanzata, coding profondo, agenti autonomi, orchestrazione di strumenti, task scientifici, capacità emergenti. Ma i modelli aperti e locali stanno diventando abbastanza buoni per il lavoro ordinario dell’intelligenza: leggere, spiegare, discutere, riassumere, classificare, trasformare, consigliare.
E l’ordinario, nella storia economica, è quasi sempre più importante dello straordinario.
Google stessa presenta Gemma 4 come una famiglia di modelli open weight, utilizzabili per generazione, question answering, riassunto e ragionamento, con possibilità di tuning e deployment in progetti propri. Il model card ufficiale parla di modelli multimodali, varianti pre-trained e instruction-tuned, finestra di contesto fino a 256K token e supporto multilingue esteso. Inoltre, Google dichiara che Gemma 4 31B si colloca tra i migliori modelli aperti nella Arena AI text leaderboard e supera modelli molto più grandi in alcuni confronti specifici. 
Questo è importante perché cambia la narrativa. Fino a ieri, il modello piccolo era spesso percepito come una versione povera del modello grande. Un compromesso temporaneo. Un giocattolo da sviluppatori. Una cosa da mettere “in soffitta” in attesa di tempi migliori.
Forse quei tempi migliori sono arrivati.
Naturalmente bisogna evitare l’euforia facile. I benchmark sono utili, ma non sono la realtà. Una leaderboard non ti dice come un modello si comporta nella tua azienda, con i tuoi dati, i tuoi utenti, i tuoi errori, le tue responsabilità legali. E soprattutto non bisogna confondere “open weight” con “open source” in senso pieno. Avere i pesi non significa necessariamente avere tutto: dataset, ricette di training, pipeline, filtri, decisioni progettuali.
Però il segnale è chiaro: l’intelligenza-per-parametro sta migliorando rapidamente.
Qwen 3.5 va nella stessa direzione. La pagina Hugging Face del modello Qwen3.5-35B-A3B mostra un ecosistema orientato al deployment locale e al serving efficiente; fonti di settore descrivono la famiglia Qwen 3.5 come una linea ampia, dal modello edge fino a modelli molto più grandi, con attenzione a tool calling, agentic benchmark e deployment più leggero. 
Questo spiega perché il dibattito sulla dimensione dei modelli sta diventando meno interessante. La domanda non è più soltanto: “Quanto è grande il modello?”. La domanda diventa: “Quanta intelligenza utile riesce a produrre per watt, per euro, per gigabyte, per secondo, per livello di rischio accettabile?”.
È una domanda molto meno spettacolare. Ma è la domanda che decide i mercati.
I giganti del closed-source non scompariranno. Anzi, i loro piani di sviluppo non sono necessariamente esagerati. Oggi solo una minoranza della popolazione mondiale usa davvero l’AI in modo sistematico. Se l’adozione crescerà anche solo di pochi punti percentuali, la domanda di capacità computazionale esploderà. Ci sarà spazio per modelli enormi, cloud hyperscale, agenti avanzati e sistemi specializzati.
Ma ci sarà anche un secondo mondo.
Un mondo on-edge.
Un mondo in cui una parte crescente dell’intelligenza artificiale gira sul laptop, sul telefono, nel server aziendale, nella fabbrica, nell’ospedale, nel veicolo, nel dispositivo personale. Un mondo in cui il cloud non scompare, ma diventa il luogo dei compiti eccezionali, mentre il dispositivo locale gestisce la normalità.
È qui che i produttori di hardware potrebbero trovare una nuova narrativa. Per anni smartphone e laptop sono diventati più potenti senza che l’utente medio avesse una ragione davvero convincente per accorgersene. Schermi migliori, batterie migliori, fotocamere migliori, ma la domanda rimaneva: a cosa serve tutta questa potenza?
Ora la risposta potrebbe essere: serve a far girare intelligenza privata.
Non è un caso che Apple stia insistendo sempre di più sull’AI on-device. Nel comunicato ufficiale del chip M5, Apple parla di miglioramenti per Apple Intelligence, Neural Engine, unified memory e performance più alte per modelli e funzionalità AI locali.  Anche altri osservatori hanno notato come l’M5 spinga su accelerazione AI, memoria e generazione locale, pur con la prudenza necessaria quando si parla di prestazioni reali fuori dai benchmark. 
Apple sembra spesso in ritardo sull’AI generativa. Ma questa potrebbe essere una lettura troppo superficiale. Se il prossimo capitolo non sarà solo “chi ha il chatbot più potente nel cloud”, ma “chi riesce a portare intelligenza utile, privata e integrata sul dispositivo”, allora Apple potrebbe trovarsi in una posizione migliore di quanto sembri.
Vedremo se e quanto emergerà già alla WWDC 2026. Ma la direzione industriale è chiara: l’AI non vivrà solo nei data center. Vivrà anche nei device.
Questo apre un bivio anche per le aziende.
Fino a oggi molte imprese hanno vissuto l’AI con una tensione irrisolta. Da un lato, vogliono usare modelli potenti. Dall’altro, hanno dati riservati, vincoli normativi, proprietà intellettuale, segreti commerciali, contratti con clienti, responsabilità di compliance. Il cloud è comodo, ma non sempre rassicurante. Il modello locale è rassicurante, ma fino a poco tempo fa non era abbastanza bravo.
Se questa seconda condizione cambia, cambia tutto.
Un’azienda potrà immaginare architetture ibride molto più sensate: modelli locali per gestire contesto sensibile, documenti interni, conversazioni riservate, classificazioni, retrieval, sintesi e workflow quotidiani; modelli cloud per i task più difficili, purché depurati dal contesto sensibile. L’orchestrazione potrà avvenire localmente. La parte privata resterà privata. La parte “intelligente ma non segreta” potrà andare verso il cloud.
Questa, a mio avviso, è una delle direzioni più interessanti: non fine-tuning ovunque, non piccoli modelli miracolosi per ogni cosa, ma orchestrazione locale intelligente.
Sul fine-tuning resto scettico. È utile in alcune nicchie: linguaggi specifici, formati ripetitivi, domini molto controllati, classificazioni verticali, tone of voice aziendale. Ma per molti casi d’uso viene sopravvalutato. Spesso le aziende non hanno bisogno di addestrare un modello. Hanno bisogno di dargli il contesto giusto, nel momento giusto, con il livello giusto di autorizzazione, e di non far uscire dati dove non dovrebbero uscire.
La vera innovazione potrebbe essere meno romantica del previsto: routing, caching, retrieval, policy, privacy, distillazione, quantizzazione, valutazione continua. Non un singolo cervello onnipotente, ma una burocrazia efficiente di piccoli cervelli specializzati.
Anche Andrej Karpathy ha rilanciato più volte un’idea simile: non tutta la strada passa dall’aumentare indefinitamente la scala; la qualità dei dati, la compressione della conoscenza e l’efficienza del training contano enormemente. Nell’intervista con Dwarkesh Patel, Karpathy insiste sul fatto che molti problemi dell’AI attuale non sono risolti solo aggiungendo scala, e che il percorso verso agenti affidabili richiederà ancora anni di lavoro.  La versione estrema di questa tesi — l’idea che un modello molto piccolo, addestrato su dati eccezionali, possa avvicinarsi a capacità oggi ottenute con modelli enormi — va presa con cautela. Non perché sia assurda, ma perché se fosse semplice OpenAI, Anthropic, Google e gli altri lo avrebbero già fatto.
Non hanno l’anello al naso.
Però è plausibile che ci sia ancora moltissimo spreco. Spreco nei dati. Spreco nei token. Spreco nei parametri. Spreco nell’inferenza. Spreco nell’uso quotidiano di modelli enormi per compiti banali.
Ed è proprio lo spreco che crea spazio economico.
Quando una tecnologia nasce, viene usata in modo inefficiente. I primi computer occupavano stanze intere per fare calcoli che oggi fa un orologio. I primi telefoni cellulari sembravano valigette. I primi modelli linguistici realmente utili sembravano dover vivere solo in enormi data center. Poi la tecnologia matura, si miniaturizza, si distribuisce, diventa invisibile.
Forse siamo all’inizio di questa fase.
Non domani mattina. Non con una rivoluzione improvvisa. Non con il crollo dei giganti del cloud. Ma con una lenta redistribuzione dell’intelligenza.
Il cloud manterrà la frontiera. L’edge conquisterà la quotidianità.
I modelli chiusi venderanno il massimo. I modelli open weight venderanno — o meglio abiliteranno — il sufficiente. E nella maggior parte dei mercati, il sufficiente vince più spesso del massimo.
Per questo l’esperienza su quell’aereo mi è sembrata più importante di quanto fosse ragionevole ammettere. Non perché Gemma 4 o Qwen 3.5 siano “la fine” dei modelli chiusi. Non lo sono. Ma perché mi hanno fatto percepire fisicamente una soglia: il momento in cui un modello locale smette di sembrare una demo e comincia a sembrare un collega.
Un collega non perfetto. A volte lento. A volte verboso. A volte impreciso. Ma disponibile, privato, economico, offline, migliorabile.
Nel 2026, forse la domanda non sarà più: “Qual è il modello migliore del mondo?”.
Sarà: “Qual è il modello più piccolo che fa abbastanza bene il lavoro?”.
E questa è una domanda pericolosa per molti business model.
Perché quando il cliente scopre che non ha sempre bisogno del tempio, comincia a costruirsi una cappella in casa.

Leave a comment